Создание семантического ядра по шагам. Семантическое ядро — как составить правильно? Шаг #3 — Сбор точной частотности для ключей
Быстрая навигация по этой странице:
Как и практически все другие вебмастеры, я составляю семантическое ядро с помощью программы KeyCollector — это безусловно лучшая программа для составления семантического ядра. Как ей пользоваться — это тема для отдельной статьи, хотя и в Интернете полно информации на этот счет — рекомендую, к примеру, мануал от Дмитрия Сидаша (sidash.ru).
Поскольку поставлен вопрос о примере составления ядра — привожу пример.
Список ключей
Предположим, у нас сайт посвящен британским кошкам. Вбиваю в «Список фраз» словосочетание «британская кошка» и нажимаю на кнопку «Парсить».
Получаю длинный список фраз, который будет начинаться со следующих фраз (приведена фраза и частнотность):
Британские кошки 75553 британские кошки фото 12421 британская вислоухая кошка 7273 питомник британских кошек 5545 кошки британской породы 4763 британская короткошерстная кошка 3571 окрасы британских кошек 3474 британские кошки цена 2461 кошка голубая британская 2302 британская вислоухая кошка фото 2224 вязка британских кошек 1888 британские кошки характер 1394 куплю британскую кошку 1179 британские кошки купить 1179 длинношерстная британская кошка 1083 беременность британской кошки 974 кошка британская шиншилла 969 кошки британской породы фото 953 питомник британских кошек москва 886 окрас британских кошек фото 882 британские кошки уход 855 британская короткошерстная кошка фото 840 шотландские и британские кошки 763 имена британских кошек 762 кошка британская голубая фото 723 фото британской голубой кошки 723 британская кошка черная 699 чем кормить британских кошек 678
Сам список намного больше, я только привел его начало.
Группировка ключей
Исходя из этого списка, у меня на сайте будут статьи про разновидности кошек (вислоухая, голубая, короткошерстная, длинношерстная), будет статья про беременность этих животных, про то, чем их кормить, про имена и так далее по списку.
Под каждую статью берется один основной такой запрос (=тема статьи). Впрочем, только одним запросом статья не исчерпывается — в нее также добавляются другие подходящие по смыслу запросы, а также разные вариации и словоформы основного запроса, которые можно найти в Кей Коллекторе ниже по списку.
Например, со словом «вислоухая» имеются следующие ключи:
Британская вислоухая кошка 7273 британская вислоухая кошка фото 2224 британская вислоухая кошка цена 513 порода кошек британская вислоухая 418 британская голубая вислоухая кошка 224 шотландские вислоухие и британские кошки 190 кошки британской породы вислоухие фото 169 британская вислоухая кошка фото цена 160 британская вислоухая кошка купить 156 британская вислоухая голубая кошка фото 129 британские вислоухие кошки характер 112 британская вислоухая кошка уход 112 вязка британских вислоухих кошек 98 британская короткошерстная вислоухая кошка 83 окрас британских вислоухих кошек 79
Чтобы не было переспама (а переспам может быть и по совокупности использования слишком большого количества ключей в тексте, в заголовке, в и т.д.), я бы не стал брать их все с включением основного запроса, но отдельные слова из них имеет смысл употребить в статье (фото, купить, характер, уход и т.д.) для того, чтобы статья лучше ранжировалась по большому количеству низко-частотных запросов.
Таким образом, у нас под статью про вислоухих кошек сформируется группа ключевых слов, которые мы употребим в статье. Точно также сформируются и группы ключевиков под другие статьи — вот и ответ на вопрос о том, как создать семантическое ядро сайта.
Частотность и конкуренция
Еще есть немаловажный момент, связанный с точной частотностью и конкуренцией — их обязательно нужно собрать в Key Collector. Для этого нужно выделить все запросы галочками и на вкладке «Частотности Yandex.Wordstat» нажать кнопку «Собрать частотности «!» — будет показана точная частнотность каждой фразы (т.е. именно с таким порядком слов и в таком падеже), это намного более точный показатель, чем общая частотность.
Для проверки конкуренции в том же Key Collector нужно нажать кнопку «Получить данные для ПС Яндекс» (или для Google), далее нажать «Рассчитать KEI по имеющимся данным». В результате программа соберет, сколько главных страниц по данному запросу находится в ТОП-10 (чем больше — тем сложнее туда пробиться) и сколько страниц в ТОП-10 содержат такой title (аналогично, чем больше — тем сложнее пробиться в топ).
Дальше нужно действовать исходя из того, какая у нас стратегия. Если мы хотим создать всеобъемлющий сайт про кошек, то нам не так важна точная частотность и конкуренция. Если же нам нужно только опубликовать несколько статей — то берем запросы, у которых самая высокая частотность и при этом самая низкая конкуренция, и на их основании пишем статьи.
Нашей статьи мы рассказали, что такое семантическое ядро и дали общие рекомендации о том, как его составить.
Пришло время разобрать этот процесс в деталях, шаг за шагом создавая семантическое ядро для вашего сайта. Запаситесь карандашами и бумагой, а главное временем. И присоединяйтесь …
Составляем семантическое ядро для сайта
В качестве примера возьмем сайт http://promo.economsklad.ru/ .
Сфера деятельности компании: складские услуги в Москве.
Сайт был разработан специалистами нашего сервиса сайт, и семантическое ядро сайта разрабатывалось поэтапно в 6 шагов:
Шаг 1. Составляем первичный список ключевых слов.
Проведя опрос нескольких потенциальных клиентов, изучив три сайта, близких нам по тематике и пораскинув собственными мозгами, мы составили несложный список ключевых слов, которые на наш взгляд отображают содержание нашего сайта: складской комплекс, аренда склада, услуги по хранению, логистика, аренда складских помещений, тёплые и холодные склады .
Задание 1: Просмотрите сайты конкурентов, посоветуйтесь с коллегами, проведите «мозговой штурм» и запишите все слова, которые, по вашему мнению, описывают ВАШ сайт.
Шаг 2. Расширение списка.
Воспользуемся сервисом http://wordstat.yandex.ru/. В строку поиска вписываем поочерёдно каждое из слов первичного списка:

Копируем уточнённые запросы из левого столбца в таблицу Excel, просматриваем ассоциативные запросы из правого столбца, выбираем среди них релевантные нашему сайту, так же заносим в таблицу.
Проведя анализ фразы «Аренда склада», мы получили список из 474 уточнённых и 2 ассоциативных запросов.


Проведя аналогичный анализ остальных слов из первичного списка, мы получили в общей сложности 4 698 уточнённых и ассоциативных запросов, которые вводили реальные пользователи в прошедшем месяце.
Задание 2: Соберите полный список запросов своего сайта, прогнав каждое из слов своего первичного списка через статистику запросов Яндекс.Вордстат .
Шаг 3. Зачистка
Во-первых, убираем все фразы с частотой показов ниже 50: «сколько стоит аренда склада » - 45 показов, «Аренда склада 200 м » - 35 показов и т.д.
Во-вторых, удаляем фразы, не имеющие отношения к нашему сайту, например, «Аренда склада в Санкт-Петербурге » или «Аренда склада в Екатеринбурге », так как наш склад находится в Москве.
Так же лишней будет фраза «договор аренды склада скачать » - данный образец может присутствовать на нашем сайте, но активно продвигаться по данному запросу нет смысла, так как, человек, который ищет образец договора, вряд ли станет клиентом. Скорее всего, он уже нашёл склад или сам является владельцем склада.
После того, как вы уберетё все лишние запросы, список значительно сократится. В нашем случае с «арендой склада» из 474 уточнённых запросов осталось 46 релевантных сайту.

А когда мы почистили полный список уточнённых запросов (4 698 фраз), то получили Семантическое Ядро сайта, состоящее из 174 ключевых запросов.
Задание 3: Почистите созданный ранее список уточнённых запросов, исключив из него низкочастоники с количеством показов меньше 50 и фразы, не относящиеся к вашему сайту.
Шаг 4. Доработка
Поскольку на каждой странице можно использовать 3-5 различных ключевиков, то все 174 запроса нам не понадобятся.
Учитывая, что сам сайт небольшой (максимум 4 страницы), то из полного списка выбираем 20, которые на наш взгляд наиболее точно описывают услуги компании.
Вот они: аренда склада в Москве, аренда складских помещений, склад и логистика, таможенные услуги, склад ответственного хранения, логистика складская, логистические услуги, офис и склад аренда, ответственное хранение грузов и так далее….
Среди этих ключевых фраз есть низкочастотные, среднечастотные и высокочастотные запросы.
Заметьте, данный список существенно отличается от первичного, взятого из головы. И он однозначно более точен и эффективен.
Задание 4: Сократите список оставшихся слов до 50, оставив только те, которые по вашему опыту и мнению, наиболее оптимальны для вашего сайта. Не забудьте, что финальный список должен содержать запросы различной частоты.
Заключение
Ваше семантическое ядро готово, теперь самое время применить его на практике:
- пересмотрите тексты вашего сайта, быть может, их стоит переписать.
- напишите несколько статей по вашей тематике, используя выбранные ключевые фразы, разместите статьи на сайте, а после того, как поисковики проиндексируют их, проведите регистрацию в каталогах статей. Читайте «Один необычный подход к статейному продвижению ».
- обратите внимание на поисковую рекламу. Теперь, когда у вас есть семантическое ядро, эффект от рекламы будет значительно выше.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :
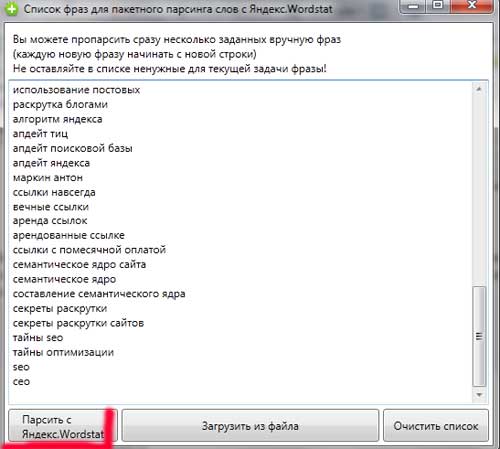
Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:

Затем проверяем стоимость получения одного перехода по нашим ключевым словам:
Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
Что такое семантическое ядро сайта? Семантическое ядро сайта (далее по тексту СЯ ) — это совокупность ключевых слов и фраз, по которым ресурс продвигается в поисковых системах и которые свидетельствуют о принадлежности сайта к определённой тематике .
Для успешного продвижения в поисковых системах, ключевые слова должны быть правильно сгруппированы и распределены по страницам сайта и в определённом виде содержаться в мета-описаниях (title , description , keywords), а также в заголовках H1-H6. При этом, нельзя допускать переспама, чтобы не «улететь» в Баден-Баден.
В этой статье мы постараемся взглянуть на вопрос не только с технической точки зрения, но и посмотреть на проблему глазами владельцев бизнеса и маркетологов.
Каким бывает сбор СЯ?
- Ручным — возможно для небольших сайтов (до 1000 ключевых слов).
- Автоматическим — программы не всегда верно определяют контекста запроса, поэтому могут возникнуть проблемы с распределением ключевиков по страницам.
- Полуавтоматическим — фразы и частотность собираются автоматически, распределение фраз и доработка происходит вручную.
В нашей статье мы рассмотрим полуавтоматический подход созданию семантического ядра, так как он является наиболее эффективным.
Кроме того, есть два типовых случая при составлении СЯ:
- для сайта с готовой структурой;
- для нового сайта .
Более предпочтительным является второй вариант, так как есть возможность составить идеальную структуру сайта под поисковые систему.
Из чего состоит процесс составления СЯ?
Работы по формированию семантического ядра делятся на следующие этапы:
- Выделение направлений, по которым будет продвигаться сайт.
- Сбор ключевых слов, анализ похожих запросов и поисковых подсказок.
- Парсинг частотности, отсев «пустых» запросов.
- Кластеризация (группировка) запросов.
- Распределение запросов по страницам сайта (составление идеальной структуры сайта).
- Рекомендации по использованию.
Чем качественней Вы составите ядро сайта, а качество в этом случае означает широту и глубину проработки семантики, тем более мощный и надёжный поток поискового трафика сможете направить на сайт и тем больше привлечёте клиентов.
Как составить семантическое ядро сайта
Итак, более подробно рассмотрим каждый пункт с различными примерами.
На первом шаге важно определить, какие товары и услуги, присутствующие на сайте будут продвигаться в поисковой выдаче Яндекса и Google.
Пример №1. Допустим на сайте есть два направления услуг: ремонт компьютеров на дому и обучение работе с Word/Exel на дому. В данном случае было принято решение, что обучение уже не пользуется спросом, поэтому его нет смысла продвигать, а значит и собирать по нему семантику. Еще один важный момент, нужно собирать не только запросы, содержащие «ремонт компьютеров на дому» , но и «ремонт ноутбуков, ремонт ПК» и прочие.
Пример №2. Компания занимается малоэтажным строительством. Но при этом строит только деревянные дома. Соответственно, запросы и семантику по направлениям «строительство домов из газобетона» или «строительство домов из кирпича» можно не собирать.
Сбор семантики
Мы рассмотрим два основных источника ключевых слов: Яндекс и Google. Расскажем, как собрать семантику бесплатно и коротко обозрим платные сервисы, позволяющие ускорить и автоматизировать данный процесс.
В Яндексе сбор ключевых фраз осуществляется из сервиса Яндекс.Вордстат и в Гугле через статистику запросов в Google AdWords. При наличии, в качестве дополнительных источников семантики, можно использовать данные Яндекс Вебмастер и Яндекс Метрики, Гугл Вебмастер и Google Analytics.
Сбор ключевых слов из Яндекс.Вордстат
Сбор запросов из Вордстата можно считать бесплатным. Для просмотра данных этого сервиса вам понадобиться только аккаунт в Яндексе. Итак, заходим на wordstat.yandex.ru и вводим ключевое слово. Рассмотрим пример сбора семантики для сайта компании по прокату авто.

Что мы видим на этом скриншоте?
- Левая колонка . Здесь обозначен основной запрос и его различные вариации с «хвостом». Напротив каждого запроса стоит число, показывающее, сколько данный запрос в общем был использован различными пользователями.
- Правая колонка . Запросы похожие на основной и показатели их общей частотности. Здесь мы видим, что человек, который хочет взять автомобиль в аренду, кроме запроса «прокат авто», может использовать «аренда авто», «прокат машин», «авто напрокат» и прочие. Это очень важные данные, на которые нужно обращать внимания, чтобы не упустить ни одного запроса.
- Региональность и история . Выбрав один из возможных вариантов, можно проверить распределение запросов по регионам, количество запросов в отдельном регионе или городе, а также тенденцию к изменениям с течением времени или со сменой времени года.
- Устройства , с которых совершался запрос. Переключая вкладки, можно узнать, с каких устройств чаще всего осуществляется поиск.
Проверяйте разные варианты ключевых фраз и полученные данные фиксируйте в таблицы Exel или в таблицах Google. Для удобства установите плагин Yandex Wordstat Helper. После его установки рядом с поисковыми фразами появятся плюсики, при нажатии на который слова будет копироваться, не нужно будет выделять и вставлять показатель частотности вручную.
Сбор ключевых слов из Google AdWords
К сожалению у Google нет открытого источника поисковых запросов с их показателями частотности, поэтому здесь нужно действовать обходными путями. И для этого нам понадобиться рабочий аккаунт в Google AdWords.
Регистрируем аккаунт в Google AdWords и пополняем баланс на минимально возможную сумму — 300 рублей (на неактивном в плане бюджета аккаунте, отображаются приблизительные данные). После этого, заходим в «Инструменты» — «Планировщик ключевых слов».

Откроется новая страница, где во вкладке «Поиск новых ключевых слов по фразе, сайту или категории» введите ключевик.

Скролим вниз, нажимаем «Получить варианты» и видим примерно такую картину.

- Основной запрос и среднее число запросов в месяц. Если аккаунт будет не проплачен, то вы увидите приблизительные данные, то есть среднее количество запросов. Когда на аккаунте есть средства, будут показаны точные данные, а также динамика изменения частотности введённого ключевика.
- Ключевые слова по релевантности. Это то же самое, что похожие запросы в Яндекс Вордстат.
- Скачивание данных. Удобен этот инструмент тем, что данные полученные в нём можно скачать.
Мы рассмотрели работу с двумя основными источниками статистики по поисковым запросам. Теперь перейдём к автоматизации этого процесса, потому что сбор семантики вручную занимает слишком много времени.
Программы и сервисы для сбора ключевых слов
Key Collector
Программа устанавливается на компьютер. В программе подключаются рабочие аккаунты от куда будет собираться статистика. Далее создаётся новый проект и папка для ключевых слов.
Выбираем «Пакетный сбор слов из левой колонки Yandex.Wordstat», вводим запросы, по которым собираем данные.

На скриншоте введён пример, на самом деле для более полного СЯ, здесь дополнительно нужно собрать все варианты запросов с марками автомобилей и классами. Например, «bmw на прокат», «купить toyota с правом выкупа», «аренда внедорожника» и так далее.
СловоЕб
Бесплатный аналог предыдущей программы. Это можно считать, как плюсом — не нужно платить, так и минусом — у программу значительно урезан функционал.
Для сбора ключевых слов, действия те же.
Rush-analytics.ru
Онлайн сервис. Его основное преимущество — не нужно ничего скачивать и устанавливать. Зарегистрировался и пользуйся. Сервис платный, но при регистрации на вашем счету есть 200 монет, чего вполне хватит, чтобы собрать небольшую семантику (до 5000 запросов) и спарсить частотность.
Минус — сбор семантики только из Wordstat.
Проверка частотности ключевых слов и запросов

И опять замечаем уменьшение количества запросов. Идём дальше и попробуем другую словоформу того же запроса.

Отмечаем, что в единственном числе, данный запрос ищет гораздо меньшее количество пользователей, значит первоначальный запрос, для нас является более приоритетным.
Такие манипуляции необходимо провести с каждым словом и словосочетанием. Те запросы, по которым итоговая частотность оказывается равной нулю (при использование кавычек и восклицательного знака), отсеиваются, т.к. «0» — говорит о том, что такие запросы никто не вводит и эти запросы являются лишь частью других. Смысл составления семантического ядра состоит в том, чтобы отобрать запросы, которые используют люди для поиска. Все запросы затем помещаются в таблицу Exel, группируются по смыслам и распределяются по страницам сайта.

В ручную это сделать просто не реально, поэтому в интернете существует множество сервисов, платных и бесплатных, которые позволяют сделать это автоматически. Приведём несколько:
- megaindex.com;
- rush-analytics.ru;
- tools.pixelplus.ru ;
- key-collector.ru.
Удаляем нецелевые запросы
После просева ключевиков следует удалить не нужные. Какие поисковые запросы можно удалять из списка?
- запросы с названиями фирм конкурентов (можно оставить в контекстной рекламе );
- запросы товаров или услуг, которые Вы не продаёте;
- запросы, где указывается район или область, в которой Вы не работаете.
Кластеризация (группировка) запросов под страницы сайта
Суть данного этапа — объединить похожие по смыслу запросы в кластеры, а затем определить на какие страницы они будут продвигаться. Как же понять какие запросы продвигать на одну страницу, а какие на другую?
1. По типу запроса.
Нам уже известно, что все запросы в поисковых системах делятся на несколько видов, в зависимости от цели поиска:
- коммерческие (купить, продажа, заказать) — продвигаются на посадочные страницы, страницы товарных категорий, карточки товаров, страницы с услугами, прайсы;
- информационные (где, как, зачем, почему) — статьи, темы форумов, рубрика ответ на вопрос;
- навигационные (телефон, адрес, название бренда) — страница с контактами.
Если сомневаетесь, к какому типу относится запрос, введите его строку поиска и проанализируйте выдачу. По коммерческому запросу будет больше страниц с предложением услуг, по информационному — статей.
Также есть геозависимые и геонезависимые запросы . Большинство коммерческих запросов является геозависимыми, так как люди в большей степени доверяют компаниям, находящихся в их городе.
2. Логика запроса.
- «купить iphone x» и «iphone x цена» — нужно продвигать на одну страницу, так как и в первом и во втором случае, осуществляется поиск одного и того же товара, и более подробной информации о нём;
- «купить iphone» и «купить iphone x» — нужно продвигать на разные страницы, так как в первом запросе мы имеем дело с общим запросом (подойдёт для товарной категории, где расположились айфоны), а во втором пользователь ищет конкретный товар и этот запрос следует продвигать на карточку товара;
- «как выбрать хороший смартфон» — данный запрос логичнее продвигать на статью блога с соответствующим названием.
Посмотреть поисковую выдачу по ним. Если, проверить, на какие страницы у различных сайтов ведут запросы «строительство домов из бруса» и «строительство домов из кирпича», то в 99% случаев это разные страницы.
4. Автоматическая группировка с помощью ПО и ручная доработка.
1-ый и 2-ой способы отлично подходят для составления семантического ядра небольших сайтов, где собрано максимум 2-3 тысячи ключевых слов. Для большого СЯ (от 10000 до бесконечности запросов), нужна помощь машин. Вот несколько программ и сервисов, которые позволяют выполнять кластеризацию:
- KeyAssistant — assistant.contentmonster.ru;
- semparser.ru;
- just-magic.org;
- rush-analytics.ru;
- tools.pixelplus.ru ;
- key-collector.ru.
После завершения автоматической кластеризации, необходимо проверить результат работ программы в ручную и если допущены ошибки — исправлять.
Пример: программа может отправить в один кластер следующие запросы: «отдых в сочи 2018 отель» и «отдых в сочи 2018 отель бриз» — в первом случае пользователь ищет различные варианты отелей для проживания, а во втором, конкретный отель.
Чтобы исключить возникновение подобных неточностей, требуется вручную всё проверять и при обнаружении ошибок, править.
Что делать дальше, после составления семантического ядра?
На основе собранного семантического ядра, далее мы:
- составляем идеальную структуру (иерархию) сайта, с точки зрения поисковых систем;
или по согласованию с заказчиком меняем структуру старого сайта; - пишем технические задания для копирайтеров по написанию тексту с учётом того кластера запросов, которые будут на эту страниц продвигаться;
или дорабатываем старые статьи тексты на сайте.
Выглядит это примерно так.

Под каждый сформированный кластер запроса мы создаём страницу на сайте и определяем ему место в структуре сайта. Наиболее популярные запросы, продвигаются на самые верхние страницы в иерархии ресурса, менее популярные располагаются под ними.
И для каждой из этих страниц, у нас уже собраны запросы, которые мы будем на них продвигать. Далее пишем ТЗ копирайтерам, чтобы сделать текст для этих страниц.
Техническое задания для копирайтера
Как и в случае со структурой сайта, опишем этот этап в общих чертах. Итак, техническое задание на текст:
- количество символов без пробела;
- заголовок страницы;
- подзаголовки (если будут);
- список слов (на основе нашего ядра), которые должны быть в тексте;
- требование по уникальности (всегда требуйте 100% уникальности);
- желаемый стиль текста;
- прочие требования и пожелания по тексту.
Помните не надо пытаться продвигать на одну страницу +100500 запросов, ограничьтесь 5-10 +хвост, иначе получите бан за переоптимизацию и надолго вылетите из игры за места в ТОПе.
Вывод
Составление семантического ядра сайта — кропотливый и тяжёлый труд, которому нужно уделить особо пристальное внимание, потому что именно на нём базируется дальнейшее продвижение сайта. Следуйте простой инструкции, приведённой в этой статье и действуйте.
- Выберите направление продвижения.
- Соберите все возможные запросы из Яндекс и Google (используйте специальные программы и сервисы).
- Проверьте частотность запросов и избавьтесь от пустышек (у которых частотность — 0).
- Удалите нецелевые запросы — услуги и товары, которые вы не продаёте, запрос с упоминание конкурентов.
- Сформируйте кластеры запросов и распределите их по страницам.
- Создайте идеальную структура сайта и составляйте ТЗ по наполнению сайта.