Использованием протоколов peer to peer. Что такое р2р видеонаблюдение. Известные децентрализованные и гибридные сети
Одна из первых пиринговых сетей, создана в 2000 г. Она функционирует до сих пор, хотя из-за серьезных недостатков алгоритма пользователи в настоящее время предпочитают сеть Gnutella2 .
При подключении клиент получает от узла, с которым ему удалось соединиться, список из пяти активных узлов; им отсылается запрос на поиск ресурса по ключевому слову. Узлы ищут у себя соответствующие запросу ресурсы и, если не находят их, пересылают запрос активным узлам вверх по “дереву” (топология сети имеет структуру графа типа “дерево”), пока не найдется ресурс или не будет превышено максимальное число шагов. Такой поиск называется размножением запросов (query flooding).
Понятно, что подобная реализация ведет к экспоненциальному росту числа запросов и соответственно на верхних уровнях “дерева” может привести к отказу в обслуживании, что и наблюдалось неоднократно на практике. Разработчики усовершенствовали алгоритм, ввели правила, в соответствии с которыми запросы могут пересылать вверх по “дереву” только определенные узлы - так называемые выделенные (ultrapeers), остальные узлы (leaves) могут лишь запрашивать последние. Введена также система кеширующих узлов.
В таком виде сеть функционирует и сейчас, хотя недостатки алгоритма и слабые возможности расширяемости ведут к уменьшению ее популярности.
Недостатки протокола Gnutella инициировали разработку принципиально новых алгоритмов поиска маршрутов и ресурсов и привели к созданию группы протоколов DHT (Distributed Hash Tables) - в частности, протокола Kademlia, который сейчас широко используется в наиболее крупных сетях.
Запросы в сети Gnutella пересылаются по TCP или UDP, копирование файлов осуществляется через протокол HTTP. В последнее время появились расширения для клиентских программ, позволяющие копировать файлы по UDP, делать XML-запросы метаинформации о файлах.
В 2003 г. был создан принципиально новый протокол Gnutella2 и первые поддерживающие его клиенты, которые были обратносовместимы с клиентами Gnutella. В соответствии с ним некоторые узлы становятся концентраторами, остальные же являются обычными узлами (leaves). Каждый обычный узел имеет соединение с одним-двумя концентраторами. А концентратор связан с сотнями обычных узлов и десятками других концентраторов. Каждый узел периодически пересылает концентратору список идентификаторов ключевых слов, по которым можно найти публикуемые данным узлом ресурсы. Идентификаторы сохраняются в общей таблице на концентраторе. Когда узел “хочет” найти ресурс, он посылает запрос по ключевому слову своему концентратору, последний либо находит ресурс в своей таблице и возвращает ID узла, обладающего ресурсом, либо возвращает список других концентраторов, которые узел вновь запрашивает по очереди случайным образом. Такой поиск называется поиском с помощью метода блужданий (random walk).
Примечательной особенностью сети Gnutella2 является возможность размножения информации о файле в сети без копирования самого файла, что очень полезно с точки зрения отслеживания вирусов. Для передаваемых пакетов в сети разработан собственный формат, похожий на XML, гибко реализующий возможность наращивания функциональности сети путем добавления дополнительной служебной информации. Запросы и списки ID ключевых слов пересылаются на концентраторы по UDP.
Вот перечень наиболее распространенных клиентских программ для Gnutella и Gnutella2: Shareaza, Kiwi, Alpha, Morpheus, Gnucleus, Adagio Pocket G2 (Windows Pocket PC), FileScope, iMesh, MLDonkey
Бесплатный P2P-клиент с открытым кодом, для работы с сетью Direct Connect. Позволяет свободно скачивать файлы, расшаренные другими пользователями этой сети.
О пиринговых сетях (p2p)
Сеть Direct Connect по своей структуре чем-то напоминает тот же BitTorrent .
Хаб Хаб (англ. hub, ступица колеса, центр) - узел сети.Трекер - сервер сети BitTorrent, координирующий её клиентов.
Здесь тоже нет централизованной системы поиска, а для того, чтоб найти какой-либо файл, нужно посетить один из специальных серверов – хабов (аналогично трекерам на BitTorrent).
Соединившись с хабом, Вы получите список пользователей, подключенных к нему. Однако соединение может не произойти, если Вы не расшарили (не выложили для скачивания) нужного объема информации. Обычно от 2 до 10 Гб.
Если соединение все же произошло, то Вы имеете возможность либо ввести на поиск имя интересующего Вас файла, либо вести поиск вручную, заходя к каждому пользователю.
Принцип работы сети должен быть в общих чертах понятен. Теперь приступим к рассмотрению самого клиента для Direct Connection.
Установка StrongDC++
Скачав архив с программой, запускаем исполняемый файл и программа установится в папку «Program files» на вашем компьютере.
Если в конце установки Вы не убрали соответствующую галочку, то программа автоматически запустится.
Данная версия уже на русском языке, но если Вы скачали английскую версию, то русифицировать программу можно с помощью соответствующего файла с расширением xml , лежащего в нашем архиве с программой.
Когда русификатор скачан, его нужно установить. Для этого выбираем в меню настроек программы пункт «Appearance» и в поле Language file нажмем кнопку «Browse», чтобы выбрать местоположение файла sDC+++russian.xml (название файла русификатора).
После проведения всех манипуляций перезапустите программу и получите полнофункциональную русскую версию!
Настройка StrongDC++
Теперь настроим уже русскую версию Strong DC ++.

В меню «Общие» следует указать свой ник, E-mail, а также скорость отдачи файлов. Поле «Описание» можно оставить пустым (это типа Ваш комментарий).
IP-адрес - цифровой адрес компьютера в сети, например: 192.0.3.244.В «Настройках соединения» можно указать свой IP-адрес и некоторые другие данные. Особое внимание следует обратить на «Настройки входящих соединений».
Лучше использовать пассивное соединение через файервол (в противном случае файлы других пользователей у Вас не будут отображаться).
Прокси-сервер - промежуточный сервер.Трафик исходящих соединений можно перенаправить на прокси сервер, а можно оставить напрямую (скорость будет выше).
Затем выберем пункт «Скачка» и настроим папки для скачки по умолчанию и для хранения временных файлов.
А теперь – самое главное!!! Надо расшарить свои файлы. Для этого заходим в меню «Мои файлы (шара)» и в открывшемся справа окошке выбираем те файлы и папки, к которым Вы хотите открыть доступ.
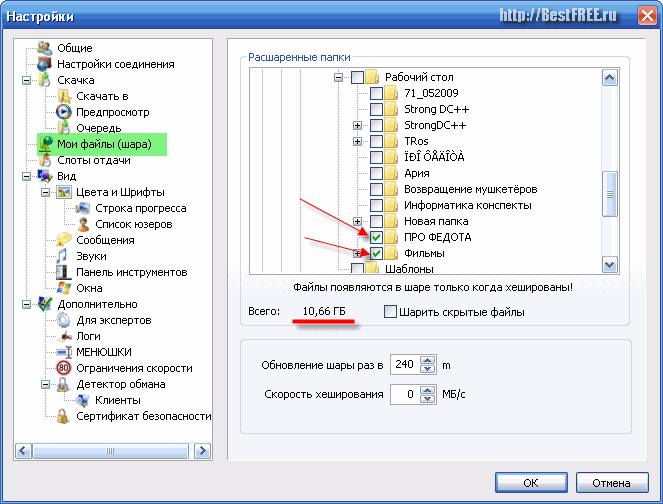
После того, как Вы выберите какой-либо файл, у Вас отобразится следующее окно прогресса.

Начало работы с StrongDC++
По истечению хеширования файлов, можно уже приступать к непосредственной работе с программой. Нажмите кнопку «OK» внизу и перед Вами появится главное окно программы.

Для того чтобы начать поиск нужных файлов, первым делом придётся подключиться к одному из многочисленных хабов.
Для этого следует нажать кнопку «Инет хабы» на панели инструментов, а далее выбрать один из списков инет хаб-листов и нажать кнопку «Обновить».

Если Вы знаете имя нужного Вам хаба или конкретного юзера, то проще производить поиск, используя фильтр.
Когда нужный хаб найден, можно переходить к нему, дважды кликнув левой кнопкой мыши по названию. Если объем расшаренных Вами данных соответствует требованиям хаба, то Вы увидите приблизительно такое окно:

Обратите внимание на наличие закладок под основным окном. При помощи этих закладок в Strong DC++ осуществляется вся навигация. Управлять закладками можно нажатием правой кнопки мыши.
Интерфейс StrongDC++
Основное пространство занимает чат – очень выгодная вещь. Он будет полезен, начиная c того, чтобы «просто поболтать», до возможности узнать у других, где найти ту или иную информацию, если поиск не помог.
Справа от чата находится список юзеров, которые в данный момент присутствуют на хабе. Цвета, которыми написаны имена пользователей, несут дополнительную информацию.

Ручной поиск файлов для скачивания
Рассмотрим взаимодействие при помощи ручного поиска. Возле каждого из пользователей есть индикатор количества расшаренных файлов. Если у Вас не очень высокая скорость соединения, то лучше выбирайте тех, у кого объем файлов поменьше.

Теперь, когда в «Статусе» появится сигнал о том, что список файлов скачан, внизу откроется еще одна закладка, на которой можно будет посмотреть, какие файлы находятся на компьютере у выбранного Вами юзера.
Чтобы скачать выбранный файл, нажмите на нем правой кнопкой мыши и выберите – «Скачать».

Точно так же мы поступаем, пользуясь поиском. В поисковой строке вводим название нужного нам файла и ждем.
После окончания поиска внизу Вы увидите список юзеров, которые обладают этим файлом. Вы выбираете одного из них, подключаетесь к нему и скачиваете нужные данные.
Выводы
Несмотря на многочисленные преимущества сети DC++, существуют и некоторые недостатки. Конкретно их два. Невозможность скачивания файла, если отключился источник (тот, у кого этот файл есть). И второй недостаток – это, иногда, очень долгая очередь на скачивание.
В целом же система очень даже интересная, а удобной ее делает использование программы StrongDC++.
P.S. Разрешается свободно копировать и цитировать данную статью при условии указания открытой активной ссылки на источник и сохранения авторства Руслана Тертышного.
P.P.S. Предшественниками сети P2P были FTP-серверы, к которым удобнее всего подключаться с помощью вот этой программы:
FTP-клиент FileZilla https://www..php
Peer-to-peer технологии
Выполнила:
студентка 1 курса ФМФ магистратуры
Кулаченко Надежда Сергеевна
Проверил:
Чернышенко Сергей Викторович
Москва 2011
Введение
По мере развития Интернета все больший интерес у пользователей вызывают технологии обмена файлами. Более доступная, чем раньше, Сеть и наличие широких каналов доступа позволяют значительно проще находить и закачивать нужные файлы. Не последнюю роль в этом процессе играют современные технологии и принципы построения сообществ, которые позволяют строить системы, весьма эффективные с точки зрения как организаторов, так и пользователей файлообменных сетей. Таким образом, данная тема на сегодняшний день является актуальной, т.к. постоянно появляются новые сети, а старые либо прекращают работу, либо модифицируются и улучшаются. По некоторым данным, в настоящее время в Интернете более половины всего трафика приходится на трафик файлообменных пиринговых сетей. Размеры самых крупных из них перевалили за отметку в миллион одновременно работающих узлов. Общее количество зарегистрированных участников таких файлообменных сетей во всем мире составляет порядка 100 млн.
Peer-to-peer (англ. равный равному) - древний принцип японских самураев и утопических социалистов. Он обрел настоящую популярность в конце ХХ столетия. Сейчас этот принцип используют миллионы пользователей интернета, разговаривая с друзьями из далеких стран, скачивая файлы у пользователей с которыми никогда не были знакомы.
Peer-to-peer (P2P) технологии являются одной из наиболее популярных тем на сегодняшний день. Популярность, достигнутая с помощью таких программам как Skype, Bittorrent, DirectConnect и список таких программ можно продолжать и продолжать, подтверждает потенциал peer-to-peer систем.
В данной работе я рассмотрю отдельные принципы функционирования ресурсов этой тематики, принципы функционирования популярных пиринговых сетей, активно применяемых для обмена файлами, а также проблемы их использования.
1. Napster и Gnutella - первые пиринговые сети
Первая пиринговая сеть Napster появилась в 1999 году и сразу стала известна всему Интернет-сообществу. Автором клиента был восемнадцатилетний Шон Феннинг. Napster соединил тысячи компьютеров с открытыми ресурсами. Изначально пользователи Napster обменивались mp3 файлами.
Napster позволял создать интерактивную многопользовательскую среду для некоторого специфического взаимодействия. Napster предоставляет всем подключенным к нему пользователям возможность обмениваться музыкальными файлами в формате mp3 практически напрямую: центральные серверы Napster обеспечивают возможность поиска на компьютерах всех подключенных к ним пользователей, а обмен происходит в обход центральных серверов, по схеме user-to-user. Немалая часть записей, циркулирующих в сформировавшейся вокруг Napster среде, защищена законом об авторских правах, однако распространяется бесплатно. Napster спокойно просуществовал пять месяцев, став весьма востребованным сервисом.
7 декабря Ассоциация индустрии звукозаписи Америки (RIAA) подала на компанию Napster в суд за «прямое и косвенное нарушение копирайта».
В конце концов, Napster сперва продался какой-то европейской фирме, а потом и вовсе был закрыт.
Gnutella - была создана в 2000 г программистами фирмы Nullsoft как преемница Napster. Она функционирует до сих пор, хотя из-за серьезных недостатков алгоритма пользователи в настоящее время предпочитают сеть Gnutella2. Эта сеть работает без сервера (полная децентрализация).
При подключении клиент получает от узла, с которым ему удалось соединиться, список из пяти активных узлов; им отсылается запрос на поиск ресурса по ключевому слову. Узлы ищут у себя соответствующие запросу ресурсы и, если не находят их, пересылают запрос активным узлам вверх по “дереву” (топология сети имеет структуру графа типа “дерево”), пока не найдется ресурс или не будет превышено максимальное число шагов. Такой поиск называется размножением запросов (query flooding).
Понятно, что подобная реализация ведет к экспоненциальному росту числа запросов и соответственно на верхних уровнях “дерева” может привести к отказу в обслуживании, что и наблюдалось неоднократно на практике. Разработчики усовершенствовали алгоритм, ввели правила, в соответствии с которыми запросы могут пересылать вверх по “дереву” только определенные узлы - так называемые выделенные (ultrapeers), остальные узлы (leaves) могут лишь запрашивать последние. Введена также система кеширующих узлов.
В таком виде сеть функционирует и сейчас, хотя недостатки алгоритма и слабые возможности расширяемости ведут к уменьшению ее популярности.
Недостатки протокола Gnutella инициировали разработку принципиально новых алгоритмов поиска маршрутов и ресурсов и привели к созданию группы протоколов DHT (Distributed Hash Tables) - в частности, протокола Kademlia, который сейчас широко используется в наиболее крупных сетях.
Запросы в сети Gnutella пересылаются по TCP или UDP, копирование файлов осуществляется через протокол HTTP. В последнее время появились расширения для клиентских программ, позволяющие копировать файлы по UDP, делать XML-запросы метаинформации о файлах.
В 2003 г. был создан принципиально новый протокол Gnutella2 и первые поддерживающие его клиенты, которые были обратносовместимы с клиентами Gnutella. В соответствии с ним некоторые узлы становятся концентраторами, остальные же являются обычными узлами (leaves). Каждый обычный узел имеет соединение с одним-двумя концентраторами. А концентратор связан с сотнями обычных узлов и десятками других концентраторов. Каждый узел периодически пересылает концентратору список идентификаторов ключевых слов, по которым можно найти публикуемые данным узлом ресурсы. Идентификаторы сохраняются в общей таблице на концентраторе. Когда узел “хочет” найти ресурс, он посылает запрос по ключевому слову своему концентратору, последний либо находит ресурс в своей таблице и возвращает ID узла, обладающего ресурсом, либо возвращает список других концентраторов, которые узел вновь запрашивает по очереди случайным образом. Такой поиск называется поиском с помощью метода блужданий (random walk).
Примечательной особенностью сети Gnutella2 является возможность размножения информации о файле в сети без копирования самого файла, что очень полезно с точки зрения отслеживания вирусов. Для передаваемых пакетов в сети разработан собственный формат, похожий на XML, гибко реализующий возможность наращивания функциональности сети путем добавления дополнительной служебной информации. Запросы и списки ID ключевых слов пересылаются на концентраторы по UDP.
2. P2P технологии. Принцип «клиент-клиент»
Одноранговая, децентрализованная или пиринговая (от англ. peer-to-peer, P2P - равный к равному) сеть - это оверлейная компьютерная сеть, основанная на равноправии участников. В такой сети отсутствуют выделенные серверы, а каждый узел (peer) является как клиентом, так и сервером. В отличие от архитектуры клиент-сервера, такая организация позволяет сохранять работоспособность сети при любом количестве и любом сочетании доступных узлов. Участниками сети являются пиры.
Впервые термин peer-to-peer был использован в 1984 г. компанией IBM при разработке сетевой архитектуры для динамической маршрутизации трафика через компьютерные сети с произвольной топологией (Advanced Peer to Peer Networking). В основе технологии лежит принцип децентрализации: все узлы в сети P2P равноправны, т.е. каждый узел может одновременно выступать как в роли клиента (получателя информации), так и в роли сервера (поставщика информации). «Это обеспечивает такие преимущества технологии P2P перед клиент-серверным подходом, как отказоустойчивость при потере связи с несколькими узлами сети, увеличение скорости получения данных за счет копирования одновременно из нескольких источников, возможность разделения ресурсов без “привязки” к конкретным IP-адресам, огромная мощность сети в целом и др.»[ 2]
Каждый из равноправных узлов взаимодействует напрямую лишь с некоторым подмножеством узлов сети. В случае необходимости передачи файлов между неконтактирующими напрямую узлами сети передача файлов осуществляется либо через узлы-посредники, либо по временно установленному прямому соединению (оно специально устанавливается на период передачи). В своей работе файлообменные сети используют свой собственный набор протоколов и ПО, который несовместим с протоколами FTP и HTTP и обладает важными усовершенствованиями и отличиями. Во-первых, каждый клиент такой сети, скачивая данные, позволяет подключаться к нему другим клиентам. Во-вторых, P2P-серверы (в отличие от HTTP и FTP) не хранят файлов для обмена, а их функции сводятся в основном к координации совместной работы пользователей в данной сети. Для этого они ведут своеобразную базу данных, в которой хранятся следующие сведения:
Какой IP-адрес имеет тот или иной пользователь сети;
Какие файлы размещены у какого клиента;
Какие фрагменты каких файлов где находятся;
Статистика того, кто сколько скачал себе и дал скачать другим.
Работа в типичной файлообменной сети строится следующим образом:
Клиент запрашивает в сети требуемый файл (перед этим возможно проведя поиск нужного файла по данным, хранящимся на серверах).
Если нужный файл имеется и найден, сервер отдает клиенту IP-адреса других клиентов, у которых данный файл был найден.
Клиент, запросивший файл, устанавливает «прямое» соединение с клиентом или клиентами, у которых имеется нужный файл, и начинает его скачивать (если клиент не отключен в это время от сети или не перегружен). При этом в большинстве P2P-сетей возможно скачивание одного файла сразу из нескольких источников.
Клиенты информируют сервер обо всех клиентах, которые к ним подключаются, и файлах, которые те запрашивают.
Сервер заносит в свою базу данных кто что скачал (даже если скачаны файлы не целиком).
Сети, созданные на основе технологии Peer-to-Peer, также называются пиринговыми, одноранговыми или децентрализованными. И хотя они используются сейчас в основном для разделения файлов, существует еще много других областей, где данная технология тоже успешно применяется. Это телевидение и аудиотрансляции, параллельное программирование, распределенное кэширование ресурсов для разгрузки серверов, рассылка уведомлений и статей, поддержка системы доменных имен, индексирование распределенных ресурсов и их поиск, резервное копирование и создание устойчивых распределенных хранилищ данных, обмен сообщениями, создание систем, устойчивых к атакам типа “отказ в обслуживании”, распространение программных модулей.
3. Основные уязвимые стороны P2P
Реализация и использование распределенных систем имеют не только плюсы, но и минусы, связанные с особенностями обеспечения безопасности. Получить контроль над столь разветвленной и большой структурой, какой является сеть P2P, или использовать пробелы в реализации протоколов для собственных нужд - желанная цель для хакеров. К тому же защитить распределенную структуру сложнее, чем централизованный сервер.
Столь огромное количество ресурсов, которое имеется в сетях P2P, тяжело шифровать/дешифровать, поэтому большая часть информации об IP-адресах и ресурсах участников хранится и пересылается в незашифрованном виде, что делает ее доступной для перехвата. При перехвате злоумышленник не только получает собственно информацию, но также узнает и об узлах, на которых она хранится, что тоже опасно.
Только в последнее время в клиентах большинства крупных сетей эта проблема стала решаться путем шифрования заголовков пакетов и идентификационной информации. Появляются клиенты с поддержкой технологии SSL, внедряются специальные средства защиты информации о местонахождении ресурсов и пр.
Серьезная проблема - распространение “червей” и подделка ID ресурсов с целью их фальсификации. Например, в клиенте Kazaa используется хеш-функция UUHash, которая позволяет быстро находить ID для больших файлов даже на слабых компьютерах, но при этом остается возможность для подделки файлов и записи испорченного файла, имеющего тот же ID.
Чтобы справиться с описанной проблемой, клиенты должны пользоваться надежными хеш-функциями (“деревьями” хеш-функций, если файл копируется по частям), такими, как SHA-1, Whirlpool, Tiger, и только для решения малоответственных задач - контрольными суммами CRC. Для уменьшения объемов пересылаемых данных и облегчения их шифрования можно применить компрессию. Для защиты от вирусов нужно иметь возможность хранить идентифицирующую метаинформацию о “червях”, как это, в частности, сделано в сети Gnutella2.
Другая проблема - возможность подделки ID серверов и узлов. При отсутствии механизма проверки подлинности пересылаемых служебных сообщений, например с помощью сертификатов, существует возможность фальсификации сервера или узла (многих узлов). Так как узлы обмениваются информацией, подделка некоторых из них приведет к компрометации всей сети или ее части. Закрытое ПО клиентов и серверов не является решением проблемы, так как есть возможность для реинжиниринга протоколов и программ (reverse engineering).
Часть клиентов только копируют чужие файлы, но не предлагают ничего для копирования другим (leechers).
В московских домовых сетях на нескольких активистов, делающих доступными более 100 Гбайт информации, приходится около сотни, выкладывающих менее 1 Гбайт. Для борьбы с этим используются разные методы. В eMule применен метод кредитов: скопировал файл - кредит уменьшился, позволил скопировать свой файл - кредит увеличился (xMule - кредитная система с поощрением распространения редких файлов). В сети eDonkey стимулируется размножение источников, в Bittorrent реализована схема “сколько блоков файла получил, столько отдал” и т. п.
4. Некоторые пиринговые сети
4.1 DirectConnect
пиринговый сеть torrent одноранговый
Direct Connect - это частично централизованная файлообменная (P2P) сеть, в основе работы которой лежит особый протокол, разработанный фирмой NeoModus.
NeoModus была основана Джонатаном Хессом (Jonathan Hess) в ноябре 1990 года как компания, зарабатывавшая на adware-программе «Direct Connect». Первым сторонним клиентом стал «DClite», который никогда полностью не поддерживал протокол. Новая версия Direct Connect уже требовала простой ключ шифрования для инициализации подключения, этим он надеялся блокировать сторонние клиенты. Ключ был взломан и автор DClite выпустил новую версию своей программы, совместимой с новым программным обеспечением от NeoModus. Вскоре, код DClite был переписан, и программа была переименована в Open Direct Connect. Кроме всего прочего, ее пользовательский интерфейс стал многодокументным (MDI), и появилась возможность использовать плагины для файлообменных протоколов (как в MLDonkey). У Open Direct Connect также не было полной поддержки протокола, но появился под Java. Немногим позже, начали появляться и другие клиенты: DCTC (Direct Connect Text Client), DC++ и др.
Сеть работает следующим образом. Клиенты подключаются к одному или нескольким серверам, так называемым хабам для поиска файлов, которые обычно не связаны между собой (некоторые типы хабов можно частично или полностью связать в сеть, используя специализированные скрипты или программу Hub-Link) и служат для поиска файлов и источников для их скачивания. В качестве хаба чаще всего используются PtokaX, Verlihub, YnHub, Aquila, DB Hub, RusHub. Для связи с другими хабами используются т.н. dchub-ссылки:
dchub://[ имя пользователя ]@[ IP или Домен хаба ]:[ порт хаба ]/[путь к файлу]/[имя файла]
Отличия от других P2P-систем:
1. Обусловленные структурой сети
· Развитый многопользовательский чат
· Сервер сети (хаб) может быть посвящен определенной теме (например музыке конкретного направления), что позволяет легко находить пользователей с требуемой тематикой файлов
· Присутствие привилегированных пользователей - операторов, обладающих расширенным набором возможностей управления хабом, в частности, следящих за соблюдением пользователями правил чата и файлообмена
2. Зависящие от клиента
· Возможность скачивать целые директории
· Результаты поиска не только по названиям файлов, но и по директориям
· Ограничения на минимальное количество расшаренного материала (по объёму)
· Поддержка скриптов с потенциально безграничными возможностями как на клиентской стороне, так и на стороне хаба (верно не для всяких хабов и клиентов)
Авторы клиента DC++ разработали для решения специфичных проблем принципиально новый протокол, называнный Advanced Direct Connect (ADC), цель которого - повышение надежности, эффективности и безопасности файлообменной сети. 2 декабря 2007 года вышла окончательная версия протокола ADC 1.0. Протокол продолжает развиваться и дополняться.
4.2 Bit Torrent
BitTorrent (букв. англ. «битовый поток») - пиринговый (P2P) сетевой протокол для кооперативного обмена файлами через Интернет.
Файлы передаются частями, каждый torrent-клиент, получая (скачивая) эти части, в то же время отдаёт (закачивает) их другим клиентам, что снижает нагрузку и зависимость от каждого клиента-источника и обеспечивает избыточность данных. Протокол был создан Брэмом Коэном, написавшим первый torrent-клиент «BitTorrent» на языке Python 4 апреля 2001 года. Запуск первой версии состоялся 2 июля 2001 года.
Для каждой раздачи создаётся файл метаданных с расширением.torrent, который содержит следующую информацию:
URL трекера;
Общую информацию о файлах (имя, длину и пр.) в данной раздаче;
Контрольные суммы (точнее, хеш-суммы SHA1) сегментов раздаваемых файлов;
Passkey пользователя, если он зарегистрирован на данном трекере. Длина ключа устанавливается трекером.
Необязательно:
Хеш-суммы файлов целиком;
Альтернативные источники, работающие не по протоколу BitTorrent. Наиболее распространена поддержка так называемых web–сидов (протокол HTTP), но допустимыми также являются ftp, ed2k, magnet URI.
Файл метаданных является словарем в bencode формате. Файлы метаданных могут распространяться через любые каналы связи: они (или ссылки на них) могут выкладываться на веб-серверах, размещаться на домашних страницах пользователей сети, рассылаться по электронной почте, публиковаться в блогах или новостных лентах RSS. Также есть возможность получить info часть публичного файла метаданных напрямую от других участников раздачи благодаря расширению протокола "Extension for Peers to Send Metadata Files". Это позволяет обойтись публикацией только магнет-ссылки. Получив каким-либо образом файл с метаданными, клиент может начинать скачивание.
Перед началом скачивания клиент подсоединяется к трекеру по адресу, указанному в торрент-файле, сообщает ему свой адрес и хеш-сумму торрент-файла, на что в ответ клиент получает адреса других клиентов, скачивающих или раздающих этот же файл. Далее клиент периодически информирует трекер о ходе процесса и получает обновлённый список адресов. Этот процесс называется объявлением (англ. announce).
Клиенты соединяются друг с другом и обмениваются сегментами файлов без непосредственного участия трекера, который лишь хранит информацию, полученную от подключенных к обмену клиентов, список самих клиентов и другую статистическую информацию. Для эффективной работы сети BitTorrent необходимо, чтобы как можно больше клиентов были способны принимать входящие соединения. Неправильная настройка NAT или брандмауэра могут этому помешать.
При соединении клиенты сразу обмениваются информацией об имеющихся у них сегментах. Клиент, желающий скачать сегмент (личер), посылает запрос и, если второй клиент готов отдавать, получает этот сегмент. После этого клиент проверяет контрольную сумму сегмента. Если она совпала с той, что записана в торрент-файле, то сегмент считается успешно скачанным, и клиент оповещает всех присоединенных пиров о наличии у него этого сегмента. Если же контрольные суммы различаются, то сегмент начинает скачиваться заново. Некоторые клиенты банят тех пиров, которые слишком часто отдают некорректные сегменты.
Таким образом, объем служебной информации (размер торрент-файла и размер сообщений со списком сегментов) напрямую зависит от количества, а значит, и размера сегментов. Поэтому при выборе сегмента необходимо соблюдать баланс: с одной стороны, при большом размере сегмента объем служебной информации будет меньше, но в случае ошибки проверки контрольной суммы придется скачивать еще раз больше информации. С другой стороны, при малом размере ошибки не так критичны, так как необходимо заново скачать меньший объём, но зато размер торрент-файла и сообщений об имеющихся сегментах становится больше.
Когда скачивание почти завершено, клиент входит в особый режим, называемый end game. В этом режиме он запрашивает все оставшиеся сегменты у всех подключенных пиров, что позволяет избежать замедления или полного «зависания» почти завершенной закачки из-за нескольких медленных клиентов.
Спецификация протокола не определяет, когда именно клиент должен войти в режим end game, однако существует набор общепринятых практик. Некоторые клиенты входят в этот режим, когда не осталось незапрошенных блоков, другие - пока количество оставшихся блоков меньше количества передающихся и не больше 20. Существует негласное мнение, что лучше поддерживать количество ожидаемых блоков низким (1 или 2) для минимизации избыточности, и что при случайном запрашивании меньший шанс получить дубликаты одного и того же блока.
Недостатки и ограничения
· Недоступность раздачи – если нет раздающих пользователей (сидов);
· Отсутствие анонимности:
Пользователи незащищенных систем и клиентов с известными уязвимостями могут быть подвергнуты атаке.
Возможно узнать адреса пользователей, обменивающихся контрафактным контентом и подать на них в суд.
· Проблема личеров – клиентов, которые раздают гораздо меньше, чем скачивают. Это ведет к падению производительности.
· Проблема читеров – пользователей, модифицирующих информацию о количестве скачанных\переданных данных.
Персонализация – протокол не поддерживает ников, чата, просмотра списка файлов пользователя.
Заключение
Современные пиринговые сети претерпели сложную эволюцию и стали во многих отношениях совершенными программными продуктами. Они гарантируют надежную и высокоскоростную передачу больших объемов данных. Они имеют распределённую структуру, и не могут быть уничтожены при повреждении нескольких узлов.
Технологии, опробованные в пиринговых сетях, применяются сейчас во многих программах из других областей:
Для скоростного распространения дистрибутивов опенсорсных программ (с открытым кодом);
Для распределённых сетей передачи данных таких как Skype и Joost.
Однако системы обмена данными часто используются в противоправной сфере: нарушаются закон об авторских правах, цензура и т.д. Можно сказать следующее: разработчики пиринговых сетей отлично понимали, для чего те будут использоваться, и позаботились об удобстве их использования, анонимности клиентов и неуязвимости системы в целом. Программы и системы обмена данными часто относят к «серой» зоне интернета - зоне, в которой нарушается законодательство, но доказать виновность причастных к нарушению лиц или сложно, или невозможно.
Программы и сети обмена данными находятся где-то на «окраине» интернета. Они не пользуются поддержкой крупных компаний, иногда им вообще никто не содействует; их создатели, как правило, хакеры, которым не по душе интернет-стандарты. Программы обмена данными не любят производители брандмауэров, маршрутизаторов и подобного оборудования, а также интернет-провайдеры (ISP) - «хакерские» сети отбирают у них значительную часть драгоценных ресурсов. Поэтому провайдеры пытаются всячески вытеснить и запретить системы обмена данными или ограничить их деятельность. Однако в ответ на это создатели систем обмена данными снова начинают искать противодействия, и часто добиваются отличных результатов.
Реализация и использование распределенных систем имеют не только плюсы, но и минусы, связанные с особенностями обеспечения безопасности. Получить контроль над столь разветвленной и большой структурой, какой является сеть P2P, или использовать пробелы в реализации протоколов для собственных нужд - желанная цель для хакеров. К тому же защитить распределенную структуру сложнее, чем централизованный сервер.
Столь огромное количество ресурсов, которое имеется в сетях P2P, тяжело шифровать/дешифровать, поэтому большая часть информации об IP-адресах и ресурсах участников хранится и пересылается в незашифрованном виде, что делает ее доступной для перехвата. При перехвате злоумышленник не только получает собственно информацию, но также узнает и об узлах, на которых она хранится, что тоже опасно.
Только в последнее время в клиентах большинства крупных сетей эта проблема стала решаться путем шифрования заголовков пакетов и идентификационной информации. Появляются клиенты с поддержкой технологии SSL, внедряются специальные средства защиты информации о местонахождении ресурсов и пр.
Серьезная проблема - распространение “червей” и подделка ID ресурсов с целью их фальсификации. Например, в клиенте Kazaa используется хеш-функция UUHash, которая позволяет быстро находить ID для больших файлов даже на слабых компьютерах, но при этом остается возможность для подделки файлов и записи испорченного файла, имеющего тот же ID.
В настоящее время выделенные серверы и узлы периодически обмениваются между собой верифицирующей информацией и при необходимости добавляют поддельные серверы/узлы в черный список блокировки доступа.
Также ведется работа по созданию проектов, объединяющих сети и протоколы (например, JXTA – разработчик Билл Джой).
Список литературы
1. Ю. Н. Гуркин, Ю. А. Семенов. «Файлообменные сети P2P: основные принципы, протоколы, безопасность» // «Сети и Системы связи», №11 2006
06/02/2011 17:23 http://www.ccc.ru/magazine/depot/06_11/read.html?0302.htm
2. А. Грызунова Napster: история болезни InterNet magazine, number 22 06/02/2011 15:30 http://www.gagin.ru/internet/22/7.html
3. Современные компьютерные сети Реферат 06/02/2011 15:49 http://5ballov.qip.ru/referats/preview/106448
4. 28/01/2011 16:56 http://ru.wikipedia.org/wiki/Peer-to-peer
5. http://style-hitech.ru/peer-to-peer_i_tjekhnologii_fajloobmjena
28/01/2011 15:51
МГОУ Peer-to-peer технологии Выполнила: студентка 1 курса ФМФ магистратуры Кулаченко Надежда Сергеевна Проверил: Чернышенко Сергей ВикторовичPeer-to-peer (P2P) технологии, несомненно, являются одной из наиболее популярных тем на сегодняшний день. Популярность, достигнутая с помощью таких систем как Napster,Gnutella,Edonkey,Emule,Kazaa и список таких программ можно продолжать и продолжать,подтверждает потенциал peer-to- peer систем. В этом обзоре мы раскажем о технологии Р2Р в целом, о системах (или правильней говоря) программах обретших популярность посредством этой технологии. Ведь если хорошенько ко всему этому присмотреться,можно понять что технология Р2Р может послужить введением для всех новых сторонников, разработчиков, и просто любителей, желающих заняться разработкой P2P приложений.
Что такое P2P ?
На сегодняшний день, наиболее распространенной моделью является Client/Server.
В Client/Server архитектуре, клиенты опрашивают сервер, и сервер возвращает необходимые данные и производит нужные операции над ними. На сегодняшний день существуют разные сервера в Inet: Web сервера, Mail сервера, FTP и т.д. Архитектура Client/Server - это пример централизованной архитектуры, где вся сеть зависит от центральных узлов, называемых серверами, предназначенных для обеспечения необходимых сервисов. Без серверов такая архитектура не имеет никакого смысла. Независимо от наличия в сети клиентов, сеть будет существовать исключительно при условии существования серверов.
Подобно архитектуре Client/Server, P2P также распределенная модель, но существует очень важная отличительная черта. В архитектуре P2P не существует понятия клиента или сервера. Каждый объект в сети, назовем его peer (англ. равный, такой же), имеет тот же статус, это означает, что этот объект может выполнять как функции клиента (отсылать запросы) так и сервера (получать ответы).
И хотя все peers имеют одинаковый статус, это не значит, что они должны иметь одинаковые физические возможности. P2P сеть может состоять из peers с разными возможностями, начиная от мобильных устройств и заканчивая mainframes. Некоторые мобильные peer могут и не поддерживать всех функциональных возможностей серверов, в силу ограничения их ресурсов (слабый процессор/небольшой объем памяти), однако сеть никак не ограничивает их.
Обе сетевые модели имеют свои преимущества и недостатки. Визуально вы можете видеть, что рост Client/Server системы (которая тем больше чем клиентов в нее добавлено) приводит к росту нагрузок на сервер. C каждым новым клиентом центральный узел слабеет. Таким образом, сеть может становиться перегруженной.
P2P сеть работает по другому сценарию. Каждый объект в сети (peer), является активным в сети, peer предоставляет некоторые ресурсы в сети, такие как пространство для хранения данных и дополнительные такты CPU. Чем больше peer в сети, тем больше производительность самой сети. Следовательно, по мере того как растет сеть, она становится мощнее.
Дополнительные отличия
Также P2P отличается от Client/Server модели тем, что P2P система считается рабочей, если в ней есть хотя бы один активный peer. Система будет считаться неактивной, если ни один peer не активен.
Недостатки технологии P2P
Однако существуют и недостатки у P2P систем. Во-первых, управление такой сетью намного сложнее, чем управление Client/Server системами, где администрирования требует только центральный узел - Server. Таким образом, нужно затратить намного больше усилий на поддержку security, backup, и т.п.
Во-вторых, P2P протокол намного более "разговорчивый" - peer может присоединиться к сети или выйти из нее в любой момент, и это может отрицательно сказаться на производительности.
Например:
Как правило, сеть состоит из равноправных узлов, причем каждый из них взаимодействует лишь с некоторым подмножеством узлов сети, так как установление связи "каждый с каждым" невозможно из-за ограниченности ресурсов (как вычислительных, так и пропускных). При этом передача информации между узлами, не связанными в данный момент непосредственно, может осуществляется как по своеобразной эстафете - от узла к узлу, так и путем установления временной прямой связи. Все вопросы маршрутизации и авторизации сообщений, передаваемых по эстафете, лежат не на едином сервере, а на всех этих отдельных узлах. Такое определение также известно под названием Pure P2P. Надеюсь все накопившиееся вопросы о том, что такое технология Peer-to-peer (P2P) исчерпаны. Теперь мы представялем вашему вниманию 5 лучших программ используемых пресловутую технологию Peer-to-peer (P2P).
Немного истории
Многие пользователи сети Интернет помнят феномен Napster"а, первой всемирной сети обмена файлами между пользователями (кстати, использовашие технолигию P2P). Napster пережил пару пинков судьбы, несколько шумных судебных процессов,в результате чего стал мягким и пушистым. Но "джин халявы" уже вылетел из бутылки…
Говоря о "первой сети обмена", я, конечно, не имел в виду, что до этого люди не обменивались файлами по сети. Любой мог послать и получить файл по почте или выложить его на ftp. Но, тем не менее, никогда ранее Сеть не потрясала такая "волна" обмена данными между пользователями - эта волна поставила под сомнение сами основы современного шоу-бизнеса.
Что же было прорывом в новой технологии?
Наверное создание гигантской распределенной базы данных, содержащей информацию "что есть у кого". Файлы классифицировались по категориям, так что можно было производить более осмысленный поиск. Так что система понимала - даже файлы с разными именами могут быть одним и тем же файлом. При этом система сама видит, у кого и сколько закачано, и подключается только к тем пользователям, что располагают частями, которых недостает вам.
Сам процесс получил название peer to peer (P2P), то есть соединение двух пользователей без использования сервера. Конечно, не так уж и "без сервера" - на самом деле серверы используются в этой схеме трижды.
Первый раз - для получения каталогов удаленных пользователей. При подключении к серверу вы отдаете ему список файлов, которые были определены вами как "общие", а взамен получаете: а) список других доступных (выделенных) серверов; б) список пользователей, которые могут выполнять роль серверов.
Другое использование серверов - это собственно операция поиска. В изначальной схеме, например eDonkey, на сервере находится общая для всех пользователей база данных общих файлов. При обращении поиска к серверу тот определяет, у кого из пользователей есть нужный файл. Эта схема в последнее время выходит из моды - серверы все реже содержат базу поиска.
Некоторые серверы могут ограничивать количество слабых клиентов или вообще запрещать их подключение. Например в системе Overnet, ID больше не зависит от свойств клиента - вместо этого клиенты явно делятся на открытых и тех, что "за файерволом".
Что осталось от Napster"а?
Первое, что бросается в глаза, когда заходишь на www.napster.com,- это сама инсталляция нового Napster"a, которая напоминает теперь инсталляцию порно-консоли или другого трояна. Я, как бы, понимаю, что загрузка exe ничем не лучше - но все равно как-то странно все это выглядит. Следующий за инсталляцией смешной момент - сообщение о том, что Napster работает только в США. А для американов - просьба зарегистрироваться и ввести имя и пароль (как видно, в Америке идет перепись медиа-"пиратов"). Короче - не ходите туда, делать там нечего.
Эпидемия Kazaa
Одним из "горячих пирожков" одно время был KaaZaa. Программа и вправду качала много чего полезного и ее имя даже стало нарицательным - однако в последнее время программа стала менее эффективной. Кроме того, количество баннеров и прочего мусора вокруг этой программы растет с ужасающей скоростью, так что теперь KaaZaa вызывает у меня ассоциации со словами "спам", "поп-ап консоли", "ускоритель интернета"… - и с соответствующими случаю эмоциями.
Итак, самые лучшие на сегодня программы - это те, что работают в сети e-Donkey2000 и Overnet. К их числу относится собственно сам e-Donkey и его детеныш - Overnet (хотя как от ослика может произойти такая медуза?), а также масса клонов. а теперь, наша лучшая пятерка.
1.- Первую позицию поделили Overnet"ом и e-Donkey
Разница между Overnet"ом и e-Donkey - в том, где производится поиск файлов. Если более старый "ослик" производил поиск на централизованном сервере или, точнее, в распределенной базе на нескольких серверах (а это узкое место - как в смысле трафика, так и в смысле Интерпола) - то более продвинутый Overnet ищет только на клиентских машинах, хотя серверы используются для прокси-услуг.По указанной причине переполненных ED серверов рекомендуется использовать Overnet, а не e-Donkey - хотя первый, в силу своей природы, может загрузить ваш трафик по полной программе. С другой стороны, количество найденных (притом редких) файлов в Overnet поражает. Плохо, что не обошлось без рекламы, но это решается мы-знаем-как.
Недостатки
Недостаток и eDonkey и Overnet: состав их инсталляции входит несколько рекламных программ, так что, если вы прозеваете этот момент и не отмените установку последних, то получите на свой винт пригоршню мусора.
2.- На второй позиции eMule и другие "ослоподобные"
В числе популярных ED-"присосок" - eMule и OneMX. Они похожи настолько, что создается даже странное ощущение, будто это вообще одна и та же программа. Что, в общем-то, так и есть: первая - Open Source, вторая - "типа бесплатная". Единственное отличие - в списке серверов по умолчанию. И если eMule, в конце концов, нашел "путь к счастью" , то OneMX вообще не смог выбраться наружу - поэтому мои познания о его работе весьма скромны. Далее речь пойдет, в основном, о eMule, получить который можно (и нужно) на www.emule-project.net . eMule поддерживает два типа сети - автоматический ED2K и Kademlia Bootstrap. Не пугайтесь, это не ругательство, а система распределенного хеша - DHT, Distributed Hash Table. Система работает так: все пользователи получают идентификаторы, и файлы получают идентификаторы, и части файлов получают идентификаторы. Сначала вы подключаетесь к паре-тройке "друзей" и как бы ненароком спрашиваете, "а как пройти в библиотеку". Поскольку ваши "кореша" уже в курсе и библиотеки и других заведений, они сбрасывают вам адреса новых серверов, где могут располагаться искомые файлы - и так далее, до победного конца. Сам процесс "раскрутки" называется Bootstrap, а система идентификации и поиска всего на свете по хеш-значениям - Kademlia.В чем тут фишка - так это в том, что eMule предлагает вам самостоятельно ввести адрес первого хоста с установленным eMule или другим Kademila-сервером, так что вы сможете от него уже передвигаться к следующим хостам - и постепенно подобраться к требующимся файлам. Можно сказать, что eMule работает и как eDonkey, запрашивая данные у серверов, и как Overnet, через Kademila,- то есть применяет оба способа поиска. Другой вопрос - откуда вы возьмете этот адрес? Вот именно. Другой "напряг" этой технологии - это то, что для "поднятия" Kademila нужно указать сервер с настоящим IP-адресом, а это не слишком распространенный сейчас метод подключения, и за NAT-фаерволом это работать не будет. Но, тем не менее,- спасибо за возможность. Приятная фича eMule - он хранит недокачанные файлы отдельно, так что вы не видите "мусора" в точке назначения (как, например, у WinMX). Поэтому точкой назначения можно указать вполне приличное место, например "Мои документы". Другая приятность - это возможность посмотреть комментарии к фалу. К сожалению, часто они бестолковы, но иногда содержат и важную информацию, например "это фильм на китайском языке" :-). Кроме прочего, eMule содержат встроенный клиент IRC для живого общения с удаленными "товарищами по несчастью" - короче, полный фарш с прикладом.
Недостатки
Чрезмерно грузит систему, и не очнь высокая скорость скачивания.
3.- На третьей позиции WinMX
Ставший весьма популярным в последнее время инструмент. Его главное отличие - полное отсутствие даже намека на рекламу и прочую "ерунду". Скачать эту примочку можно на www.winmx-download-winmx.com (сама закачка происходит с сайта Morpheus-Download, что наводит на размышления; однако другой информации на тему WinMX и Morpheus я не нашел - наверное, люди предпочитают шифроваться).
WinMX - сокращение от "Windows Media eXchange". Существует порт на Mac, для других систем портов не обнаружено.
В отличие от других p2p-клиентов WinMX не показывает ни списка серверов, ни самого процесса подключений. На самом деле средний пользователь крайне редко может извлечь из этих данных какую-то полезную для себя информацию или как-то конструктивно повлиять на ход подключения.
Закладка Поиск посвящена понятно чему - тут все ясно: вводите слова и ищете. После того как будут найдены источники, можете отпиногвать их на предмет "интересности" - хотя вы никогда не угадаете, кто вам "сольет файло", так что дискриминация тут неуместна. Разумно щелкать Download по всей группе, а не только по одному источнику - ненужные опадут сами, как осенняя листва.
Несколько непонятных сокращений вы встретите на закладке Transfers, а именно - AFS и AEQ. Это очень хорошие параметры. Первый значит Auto Find Sources и показывает период (в минутах), с каким будет выполняться попытка найти новые источники для ваших файлов. Таким образом, можно "загнать" поисковик, а можно, напротив, "попустить". Постоянно проверять новые источники нет смысла, они появляются не слишком часто - главное, никогда не устанавливайте этот параметр в Never.
Второй параметр расшифровывается как Auto EnQueue - то есть, когда вы находите файл и при этом вам предлагают стать в очередь, то в каком случае соглашаться? Для редких файлов этот параметр можно поставить в максимальное значение - 100.
AFS и AEQ по умолчанию можно настроить на закладке Configuration… почему-то Search, но не суть важно. В других клиентах таких настроек нет (или это я не нашел?).
Есть небольшой "загон" в настройках по умолчанию - вы настроены выбрасывать "inactive DL sources" каждые 10 минут. Это приводит к тому, что в один момент вы можете выбросить все источники - и закачка улетит из списка. Файл останется на месте, и вы, конечно, всегда можете "вернуть" закачку, нажав Load Incomplete - но сделать это сможете только руками… утром в понедельник, тогда как вы могли качать все выходные.
Недостатки
Многофункциональность и огромное количество настроек осложняет освоение программы рядовым пользователем.
4.- На четвертой позиции Shareaza или G2.
Shareaza (или, по-народному, Ш (З) араза) - это клиент, созданный авторами и фанатами сети Gnutella для собственных нужд:-). Shareaza поддерживает собственный протокол Gnutella2 (Mike"s Protocol, MP), протокол старой сети Gnutella 1, ED2K и BitTorrent. Поскольку MP и BitTorrent пока не получили особого распространения (хотя, все может измениться). Еще один клиент точно поддерживает G2 - mlDonkey, других обнаружить не удалось.Что хорошо - G2 имеет формальное описание, четкую систему требований и даже собственный стандарт, что может сделать эту сеть достаточно устойчивой для конкуренции с Overnet. Побочный эффект Shareaza - поскольку этот клиент обслуживает запросы сразу многих сетей, то исходящий (даже когда вы ничего и не закачиваете) трафик легко может "стартовать" до 25 Кб/с! Следите за этим, если вы выкачиваете под контролем. Ограничить скачивание можно в Config-Internet-Uploads (по умолчанию: 7 Кб/с для Core, 12 Кб/с для Partially Downloaded и по 2 Кб для каждого размера файлов, большого, среднего и малого - итого разрешенный исходящий трафик - 25 Кб/с).
5.- И наконец на пятой позиции Gnutella и BitTorrent
Самая распространенная и популярная сеть обмена (если не учитывать ED2k) называется Gnutella. Кстати, после появления Gnutella2 ее часто называют Gnutella 1 или "старая (legacy) Gnutella". В основе G1 лежит несколько другой механизм распространения запросов - но в принципе все без особых изменений. Основное отличие Gnutella - она не использует механизмы Kademlia, то есть поиск в этой сети осуществляется "вслепую", по случайным маршрутам. Лучшая критика G1 дана на сайте разработчиков Gnutella 2. - Там, например, упоминается, что в худшем случае один пользователь может "поставить на уши" 80% всей G1-сети.
Официальные программы для этой сети - BearShare (также поддерживает ED2K?), Gnucleus, Morpheus (версия: первоначально был на движке KaaZaa - FastTrack, но после "сессий" с судом Лос-Анджелеса перешел под знамена Gnutell"ы), Xolox Ultra, LimeWare, Phex. Некоторые из них написаны на Java, а некоторые даже под.NET. Каждый из этих клиентов превозносит себя как "самого": BearShare - "самый лучший", Gnucleus - "самый честный", ну и так далее.
Типичный современный клиент для сети Gnutella - LimeWire. Весь сайт LimeWare увешан надписями "быстрее, чем KaaZaa!" - хм, ну было бы чем гордиться. Главная отличительная особенность этого клиента - программа на Java. Со всеми вытекающими из этого последствиями: красиво и медленно.
Перечисленные выше программы, особенно Lime, часто просто перенасыщенны рекламой, spy-ware и прочими вещами, так что я упоминаю их тут только для полноты изложения - можете поставить эти программы в целях ознакомления, чтобы не говорили потом, будто у вас не было выбора.
Помимо того, в сети Gnutella я не нашел нужных мне файлов, так что знакомство с ней завершилось, так и не начавшись. Единственное, что порадовало, так это сайт www.gnutella.com (на движке Zope+Plone?) - хотя и там все закачки происходят через рекламный блок.
BitTorrent это технология распределенной закачки файлов, которая называется еще swarming,- то есть файл собирается в одно целое, подобно тому как пчелы собирают мед в улей. Собственно, сам BT - это серверная часть для загрузки вот таким вот образом.
Все, что нужно для настройки, описано тут. Как вы поймете, это скорее технология, чем пользовательский инструмент - по крайней мере, программы не изобилуют документацией и богатым интерфейсом.
Руководство к действию
Вы знаете, что вам нужно,- и готовы получить это любым путем. Дополнительное условие - у вас огромный канал и вы не платите за трафик. Ваши действия - можете установить параллельно три утилиты - WinMX, eMule и Shareaza - качать они будут, как показывает опыт, из разных источников. Конечно, вы будете несколько раз дублировать файлы, но ваши шансы получить их при жизни значительно возрастут. Не втрое, конечно (люди-то и серверы во всех сетях часто одни и те же) - но тем не менее.
Если у вас платное подключение и ресурсов ровно столько, чтобы хватало на "скромную роскошь" - но желание велико и за ценой вы не постоите. Все-таки еще раз пройдитесь по раскладкам - а вдруг найдете на диске? Поскольку удельная стоимость мегабайта будет впечатляющей. выбирайте eMule, это самый универсальный "ослоподобный" P2P. И именно сего помощью я и получил самые редкие файлы. Если вы любите цирк и мигающие лампочки - закачайте eMule в версии "плюс".
Другие клиенты, например WinMX, тоже способны на многое (ставить не страшно, рекламных консолей там нет).
Если у вас реально нет проблем с трафиком, можете активно пользовать Overnet - но будьте готовы к тому, что вся сеть станет публиковать на вашем узле соответствующие вашему ID фрагменты. А это, скажу я вам, не шутка - по крайней мере, обязательно ставьте ограничители трафика!
А вот уж чего делать не советую - так это ставить "бесплатные" гнутелльные софтины (если, конечно, не хотите потом всю жизнь удалять с винта тараканов). Сама-то сетка Gnutella не виновата, а вот софт-пакеры удивляют своей наглостью и желанием получать прибыль от открытого кода. Ну во и все наверное, пишите,стучите, и верьте, что на наших сайтах у меня на "ПромоNews" , и "SuperQ" Вы всегда получите ответы на столь необходимые и важные вопросы. Наш девиз звучит примерно так: "Найди себя среди друзей!" Удачи:)
При беглом знакомстве с литературой обнаруживается множество различных толкований понятия Peer-to-Peer, отличающихся в основном спектром включаемых особенностей.
Самые строгие определения «чистой» одноранговой сети трактуют ее как полностью распределенную систему, в которой все узлы являются абсолютно равноправными с точки зрения функциональности и выполняемых задач. Такому определению не соответствуют системы, основанные на идее «суперузлов» (узлов, исполняющих роль динамически назначаемых локальных мини-серверов), например Kazaa (хотя это не мешает ее широкому признанию в качестве сети P2P, или системы, использующей некоторую централизованную серверную инфраструктуру для выполнения подмножества вспомогательных задач: самонастройки, управления репутационным рейтингом и т. п.).
Согласно более широкому определению, P2P есть класс приложений, которые используют ресурсы, - жесткие диски, циклы процессора, контент, - доступные на краю облака Интернета. В то же время оно подходит и для систем, применяющих для своего функционирования централизованные серверы (таких как SETI@home, системы мгновенных сообщений или даже печально известная сеть Napster), а также различных приложений из области grid-вычислений (решетчатых вычислений).
В итоге, если говорить честно, единой точки зрения на то, что является и что не является сетью P2P, нет. Наличие множества определений, скорее всего, объясняется тем, что системы или приложения называются P2P вследствие не своих внутренних операций или архитектуры, а того, как они воспринимаются внешне, т. е. обеспечивают ли впечатление прямого взаимодействия между компьютерами.
В то же время многие сходятся во мнении, что главные для архитектуры P2P следующие характеристики:
- разделение компьютерных ресурсов путем прямого обмена без помощи посредников. Иногда могут использоваться централизованные серверы для выполнения специфических задач (самонастройка, добавление новых узлов, получение глобальных ключей для шифрования данных). Поскольку узлы одноранговой сети не могут полагаться на центральный сервер, координирующий обмен контентом и операции во всей сети, требуется, чтобы они независимо и односторонне принимали активное участие в выполнении таких задач, как поиск для других узлов, локализация или кэширование контента, маршрутизация информации и сообщений, соединение с соседними узлами и его разрыв, шифрование и верификация контента и др.;
- способность рассматривать нестабильность и непостоянство соединений как норму, автоматически адаптируясь к их разрывам и отказам компьютеров, а также к переменному количеству узлов.
Исходя из этих требований ряд специалистов предлагает такое определение (его стиль несколько напоминает патентный, но если попытаться его упростить, то получится только хуже): сеть P2P является распределенной системой, содержащей взаимосвязанные узлы, способные к самоорганизации в сетевую топологию с целью разделения ресурсов, таких как контент, циклы процессора, устройства хранения и полоса пропускания, адаптирующейся к отказам и переменному числу узлов, поддерживая при этом приемлемый уровень связности и производительности без необходимости в посредниках или поддержке глобального центрального сервера.
Здесь самое время порассуждать об особенностях вычислений в grid- и P2P-системах. И те и другие представляют два подхода к распределенным вычислениям с использованием разделяемых ресурсов в крупномасштабном компьютерном сообществе.
Вычислительные решетки - это распределенные системы, которые предусматривают крупномасштабное координированное использование и разделение географически распределенных ресурсов, базирующиеся на постоянных стандартизованных сервисных инфраструктурах и предназначенные преимущественно для высокопроизводительных вычислений. При расширении эти системы начинают требовать решения проблем самоконфигурирования и устойчивости к сбоям. В свою очередь, P2P-системы изначально ориентированы на нестабильность, переменное количество узлов в сети, устойчивость к отказам и самоадаптацию. К настоящему времени разработчики в области P2P создали в основном вертикально интегрированные приложения и не заботились об определении общих протоколов и стандартизованных инфраструктур для взаимодействия.
Однако по мере развития технологии P2P и использования более сложных приложений, таких как распределение структурированного контента, совместная работа на ПК и сетевые вычисления, ожидается конвергенция P2P- и grid-вычислений.
Классификация P2P-приложений
Архитектуры P2P использовались для множества приложений разных категорий. Приведем краткое описание некоторых из них.
Коммуникации и сотрудничество. Эта категория включает системы, обеспечивающие инфраструктуру для прямых, обычно в режиме реального времени, коммуникаций и сотрудничества между равноправными компьютерами. Примерами могут служить чат и служба мгновенных сообщений.
Распределенные вычисления. Целью этих систем является объединение вычислительных возможностей равноправных узлов для решения задач с интенсивными вычислениями. Для этого задача разбивается на ряд небольших подзадач, которые распределяются по разным узлам. Результат их работы возвращается затем хосту. Примеры таких систем - проекты SETI@home, genome@ home и ряд других.
Системы баз данных. Значительные усилия были затрачены на разработку распределенных баз данных, основанных на P2P-инфраструктуре. В частности, была предложена локальная реляционная модель (Local Relational Model), предполагающая, что набор всех данных, хранимых в P2P-сети, состоит из несовместимых локальных реляционных баз данных (т. е. не удовлетворяющих заданным ограничениям целостности), взаимосвязанных с помощью «посредников», которые определяют трансляционные правила и семантические зависимости между ними.
Распределение контента. К этой категории относится большинство современных P2P-сетей, включающих системы и инфраструктуры, разработанные для разделения цифровой аудиовизуальной информации и других данных между пользователями. Спектр таких систем для распределения контента начинается от относительно простых приложений для прямого разделения файлов и простирается до более сложных, которые создают распределенные среды хранения, обеспечивающие безопасность и эффективные организацию, индексацию, поиск, обновление и извлечение данных. В качестве примеров можно привести позднюю сеть Napster, Gnutella, Kazaa, Freenet и Groove. В дальнейшем мы сфокусируем внимание именно на этом классе сетей.
Распределение контента в сетях P2P
В самом типичном случае такие системы образуют распределенную среду хранения, в которой можно выполнить публикацию, поиск и извлечение файлов пользователями этой сети. По мере усложнения в ней могут появляться нефункциональные особенности, такие как обеспечение безопасности, анонимности, равнодоступности, масштабируемости, а также управление ресурсами и организационные возможности. Современные технологии P2P можно классифицировать следующим образом.
Приложения P2P. В эту категорию входят системы распределения контента, базирующиеся на технологии P2P. В зависимости от назначения и сложности их уместно подразделить на две подгруппы:
- системы обмена файлами , предназначенные для простого одноразового обмена между компьютерами. В таких системах создается сеть равноправных узлов и обеспечиваются средства для поиска и передачи файлов между ними. В типичном случае это «легковесные» приложения с качеством обслуживания «по мере возможности» (best effort), не заботящиеся о безопасности, доступности и живучести;
- системы для публикации и хранения контента . Такие системы предоставляют среду распределенного хранения, в которой пользователи могут публиковать, сохранять и распределять контент, при этом поддерживаются безопасность и надежность. Доступ к такому контенту контролируется, и узлы должны обладать соответствующими привилегиями для его получения. Основными задачами таких систем являются обеспечение безопасности данных и живучести сети, и зачастую их главная цель заключается в создании средств для идентифицируемости, анонимности, а также управления контентом (обновление, удаление, контроль версий).
- определение адреса и маршрутизация. Любая P2P-система распределения контента опирается на сеть равноправных узлов, внутри которой узлы и контент должны эффективно локализоваться, а запросы и ответы - маршрутизироваться, и при этом обеспечиваться отказоустойчивость. Для выполнения этих требований были разработаны различные инфраструктуры и алгоритмы;
- обеспечение анонимности. P2P-базированные инфраструктурные системы должны разрабатываться с целью обеспечения анонимности пользователя;
- репутационный менеджмент. В сетях P2P отсутствует центральный орган для управления репутационной информацией о пользователях и их поведении. Поэтому она располагается на множестве разных узлов. Для того чтобы гарантировать ее безопасность, актуальность и доступность во всей сети, необходимо иметь сложную инфраструктуру управления репутациями.
Локализация и маршрутизация распределенных объектов в сетях P2P
Функционирование любой P2P-системы распределения контента опирается на узлы и соединения между ними. Эта сеть образуется поверх и независимо от базовой (в типичном случае IP) и поэтому часто называется оверлейной. Топология, структура, степень централизации оверлейной сети, механизмы локализации и маршрутизации, которые в ней используются для передачи сообщений и контента, являются решающими для работы системы, поскольку они воздействуют на ее отказоустойчивость, производительность, масштабируемость и безопасность. Оверлейные сети различаются по степени централизации и структуре.
Централизация. Хотя самое строгое определение предполагает, что оверлейные сети полностью децентрализованы, на практике этого не всегда придерживаются, и встречаются системы с той или иной степенью централизации. В частности, выделяют три их категории:
- полностью децентрализованные архитектуры. Все узлы в сети выполняют одинаковые задачи, действуя как серверы и клиенты, и не существует центра, координирующего их активность;
- частично централизованные архитектуры. Базис здесь тот же, что и в предыдущем случае, однако некоторые из узлов играют более важную роль, действуя как локальные центральные индексы для файлов, разделяемых локальными узлами. Способы присвоения таким суперузлам их роли в сети в разных системах варьируются. Важно, однако, отметить, что эти суперузлы не являются единой точкой отказа для сети P2P, так как назначаются динамически и в случае отказа сеть автоматически передает их функции другим узлам;
- гибридные децентрализованные архитектуры. В таких системах имеется центральный сервер, который облегчает взаимодействие между узлами посредством управления директорией метаданных, описывающей хранимые на них разделяемые файлы. Хотя сквозное взаимодействие и обмен последними может осуществляться непосредственно между двумя узлами, центральные серверы облегчают этот процесс, просматривая и идентифицируя узлы, хранящие файлы.
Очевидно, в этих архитектурах имеется единая точка отказа - центральный сервер.
Сетевая структура характеризует, создается ли оверлейная сеть недетерминировано (ad hoc), по мере того как добавляются узлы и контент, или базируется на специальных правилах. С точки зрения структуры сети P2P делятся на две категории:
- неструктурированные. Размещение контента (файлов) в них никак не связано с топологией оверлейной сети, в типичных случаях его нужно локализовать. Механизмы поиска варьируются от методов грубой силы, таких как лавинное распространение запросов способами «сначала вширь» (breadth-first) или «сначала вглубь» (depth-first) - до тех пор пока желаемый контент не будет найден, до более софистических стратегий, предполагающих использование метода случайного блуждания и индексацию маршрутов. Механизмы поиска, применяемые в неструктурированных сетях, имеют очевидное влияние на доступность, масштабируемость и надежность.
Неструктурированные системы более подходят для сетей с непостоянным числом узлов. Примерами являются Napster, Gnutella, Kazaa, Edutella и ряд других;
- структурированные. Появление таких сетей в первую очередь было связано с попытками решить проблемы масштабируемости, с которыми первоначально столкнулись неструктурированные системы. В структурированных сетях оверлейная топология строго контролируется, и файлы (или указатели на них) размещаются в строго определенных местах. Эти системы, по сути, обеспечивают соответствие между контентом (скажем, идентификатором файла) и его расположением (например, адресом узла) в форме распределенной маршрутной таблицы, так что запросы могут быть эффективно направлены узлу с искомым контентом.
Структурированные системы (к ним относятся Chord, CAN (Content Addressable Network), Tapestry и ряд других) предоставляют масштабируемые решения для поиска по точному совпадению, т. е. для запросов, в которых известен точный идентификатор нужных данных. Их недостатком является сложность управления структурой, требуемая для эффективной маршрутизации сообщений в среде с переменным числом узлов.
Сети, занимающие промежуточное положение между структурированными и неструктурированными, имеют название слабоструктурированных. Хотя данные о локализации контента в них указываются не полностью, они, тем не менее, способствуют поиску маршрута (типичный пример такой сети - Freenet).
Теперь обсудим более подробно оверлейные сети с точки зрения их структуры и степени централизации.
Неструктурированные архитектуры
Начнем с полностью децентрализованных архитектур (см. приведенное выше определение). Самым интересным представителем таких сетей является Gnutella. Подобно большинству P2P-систем, она строит виртуальную оверлейную сеть с собственным механизмом маршрутизации, позволяя своим пользователям разделять файлы. В сети отсутствует какая-либо централизованная координация операций, и узлы соединяются друг с другом непосредственно с помощью ПО, которое функционирует и как клиент, и как сервер (его пользователей называют servents - от SERVers + cliENTS).
В качестве базового сетевого протокола Gnutella применяет IP, тогда как коммуникации между узлами определяются протоколом прикладного уровня, поддерживающим четыре типа сообщений:
- Ping - запрос к определенному хосту с целью объявить о себе;
- Pong - ответ на сообщение Ping, содержащий IP-адрес, порт запрошенного хоста, а также количество и размеры разделяемых файлов;
- Query - поисковый запрос. В него входят строка поиска и минимальные скоростные требования к отвечающему хосту;
- Query Hits - ответ на запрос Query , включает IP-адрес, порт и скорость передачи отвечающего хоста, количество найденных файлов и набор их индексов.
После присоединения к сети Gnutella (посредством связи с узлами, обнаруженными в базах данных, таких как gnutellahosts.com) узел посылает сообщение Ping каким-нибудь связанным с ним хостам. Те отвечают сообщением Pong , идентифицируя себя, и рассылают сообщение Ping свом соседям.
В неструктурированной системе, подобной Gnutella, единственной возможностью локализовать файл является недетерминированный поиск, так как у узлов не было способа предположить, где он находится.
Первоначально в архитектуре Gnutella использовался лавинный (или широковещательный) механизм для распределения запросов Ping и Query : каждый узел направлял полученные сообщения всем своим соседям, а ответы шли по обратному пути. Чтобы ограничить потоки сообщений в сети, все они содержали в заголовке поле Time-to-Live (TTL). На транзитных узлах значение этого поля уменьшалось, и когда оно достигало значения 0, сообщение удалялось.
Описанный механизм реализовывался посредством присвоения сообщениям уникальных идентификаторов ID и наличия в хостах динамических маршрутных таблиц с идентификаторами сообщений и адресами узлов. Когда ответы содержат такой же ID, что и исходящие сообщения, хост обращается к маршрутной таблице, чтобы определить, по какому каналу направить ответ для разрыва петли.
| Рис. 1. Пример механизма поиска в неструктурированной системе |
Если узел получает сообщение Query Hit , в котором указано, что искомый файл находится на определенном компьютере, он инициирует загрузку посредством прямого соединения между двумя узлами. Механизм поиска приведен на рис. 1.
Частично централизованные системы во многом подобны полностью децентрализованным, но они используют концепцию суперузлов - компьютеров, которым динамически присваивается задача обслуживания небольшой части оверлейной сети с помощью индексирования и кэширования содержащихся в ней файлов. Они выбираются автоматически, исходя из их вычислительной мощности и полосы пропускания.
Суперузлы индексируют файлы, разделяемые подсоединенными к ним узлами, и в качестве proxy-серверов выполняют поиск от их имени. Поэтому все запросы первоначально направляются к суперузлам.
Частично централизованные системы обладают двумя преимуществами:
- уменьшенным временем поиска по сравнению с предыдущими системами при отсутствии единой точки отказа;
- эффективным использованием присущей P2P-сетям гетерогенности. В полностью децентрализованных системах все узлы нагружаются одинаково независимо от их вычислительной мощности, полосы пропускания каналов или возможностей систем хранения. В частично централизованных системах суперузлы берут на себя большую часть сетевой нагрузки.
Частично централизованной системой является сеть Kazaa.
Рис. 2 иллюстрирует пример типичной P2P-архитектуры с гибридной децентрализацией. На каждом клиентском компьютере хранятся файлы, разделяемые с остальной оверлейной сетью. Все клиенты соединены с центральным сервером, который управляет таблицами данных о зарегистрированных пользователях (IP-адрес, пропускная способность канала и т. п.) и списков файлов, имеющихся у каждого пользователя и разделяющихся в сети наряду с метаданными файлов (например, имя, время создания и т. п.).
Компьютер, который хочет войти в сообщество, подсоединяется к центральному серверу и сообщает ему о содержащихся на нем файлах. Клиентские узлы направляют запросы о них серверу. Тот производит поиск в индексной таблице и возвращает список пользователей, у которых они находятся.
Преимущество систем с гибридной децентрализацией заключается в том, что они просто реализуются, а поиск файлов выполняется быстро и эффективно. К основным недостаткам следует причислить уязвимость для контроля, цензуры и правовых действий, атак и технических отказов, поскольку разделяемый контент или, по крайней мере, его описание управляется одной организацией, компанией или пользователем. Более того, такая система плохо масштабируется, так как ее возможности ограничиваются размером БД сервера и его способностью отвечать на запросы. Примером в данном случае может служить Napster.
Структурированные архитектуры
Разнообразные структурированные системы распределения контента используют различные механизмы для маршрутизации сообщений и нахождения данных. Мы остановимся на наиболее знакомой украинским пользователям - Freenet.
Данная оверлейная сеть принадлежит к числу слабоструктурированных. Напомним, что главной их характеристикой является способность узлов определять (не централизованно!), где с наибольшей вероятностью хранится тот или иной контент на базе таблиц маршрутизации, где указано соответствие между контентом (идентификатором файла) и его локализацией (адресом узла). Это предоставляет им возможность избегать слепого широковещательного распространения запросов. Взамен применяется метод цепочки, в соответствии с которым каждый узел принимает локальное решение, куда далее направить сообщение.
Freenet - типичный пример полностью децентрализованной слабоструктурированной системы распределения контента. Она функционирует как самоорганизующаяся одноранговая сеть, собирая в пул неиспользуемое дисковое пространство компьютеров с целью создания общей виртуальной файловой системы.
Файлы в Freenet идентифицируются с помощью уникальных двоичных ключей. Поддерживаются три типа ключей, простейший из них базируется на применении хэш-функции к короткой дескриптивной текстовой строке, которая сопровождает любой файл, сохраняемый в сети его владельцем.
Каждый узел сети Freenet управляет своим собственным локальным хранилищем данных, делая его доступным для чтения и записи остальными, так же как и динамическую таблицу маршрутизации, содержащую адреса других узлов и хранимых ими файлов. Чтобы найти файл, пользователь посылает запрос, содержащий ключ и косвенное значение времени жизни, выраженное посредством максимально допустимого количества пройденных транзитных узлов (hops-to-live).
Freenet использует следующие типы сообщений, каждое из которых включает идентификатор узла (для обнаружения петель), значение hops-to-live и идентификаторы источника и получателя:
- Data insert - узел, помещающий новые данные в сеть (в сообщении находятся ключ и данные (файл));
- Data request - запрос определенного файла (в него входит ключ);
- Data reply - ответ, когда файл найден (в сообщение включается файл);
- Data failed - ошибка в поиске файла (указываются узел и причина ошибки).
Для присоединения к Freenet компьютеры прежде всего определяют адрес одного или более существующих узлов, а затем отправляют сообщения Data insert .
Чтобы поместить новый файл в сеть, узел сначала вычисляет его двоичный ключ и посылает сообщение Data insert себе. Любой узел, получивший такое сообщение, сначала проверяет, не используется ли уже этот ключ. Если нет, то он ищет ближайший (в смысле лексикографического расстояния) в своей маршрутной таблице и направляет сообщение (с данными) соответствующему узлу. С помощью описанного механизма новые файлы размещаются на узлах, уже владеющих файлами с подобными ключами.
Это продолжается до тех пор, пока не исчерпается лимит hops-to-live . Таким образом, распространяемый файл разместится более чем на одном узле. Во то же время все узлы, вовлеченные в процесс, обновят свои маршрутные таблицы - таков механизм, посредством которого новые узлы анонсируют свое присутствие в сети. Если предел hops-to-live достигнут без коллизии значений ключей, сообщение «все корректно» будет доставлено обратно к источнику, информируя его, что файл помещен в сеть успешно. Если же ключ уже используется, узел возвращает существующий файл, как будто именно он был запрошен. Таким образом, попытка подмены файлов приведет к распространению их дальше.
При получении узлом запроса на хранящийся на нем файл поиск останавливается и данные направляются к его инициатору. Если требуемого файла нет, узел передает запрос к соседнему, на котором он с большой вероятностью может находиться. Адрес отыскивается в маршрутной таблице по ближайшему ключу, и т. д. Заметим, что здесь приведен упрощенный алгоритм поиска, дающий лишь общую картину функционирования сети Freenet.
На этом мы, пожалуй, закончим весьма конспективный обзор технологий P2P и затронем тему использования их в бизнесе. Несложно выделить ряд преимуществ P2P-архитектуры перед клиент-серверной, которые будут востребованы в деловой среде:
- высокая надежность и доступность приложений в децентрализованных системах, что объясняется отсутствием единой точки отказа и распределенным характером хранения информации;
- лучшая утилизация ресурсов, будь то пропускная способность каналов связи, циклы процессора или место на жестких дисках. Дублирование рабочей информации также существенно снижает (но не исключает полностью) потребность в резервном копировании;
- простота развертывания системы и легкость использования за счет того, что одни и те же программные модули выполняют и клиентские, и серверные функции - особенно когда речь идет о работе в локальной сети.
Потенциальные возможности сетей P2P оказались столь велики, что Hewlett-Packard, IBM и Intel инициировали создание рабочей группы с целью стандартизировать технологию для применения в коммерческих целях. В новой версии ОС Microsoft Windows Vista будут встроены средства для коллективной работы, позволяющие ноутбукам разделять данные с ближайшими соседями.
Первые сторонники этой технологии, такие как аэрокосмический гигант Boeing, нефтяная компания Amerada Hess и сама Intel, говорят, что ее использование уменьшает необходимость в приобретении высокоуровневых вычислительных систем, включая мэйнфреймы. Системы P2P могут также ослабить требования к пропускной способности сети, что важно для компаний, у которых возникают с этим проблемы.
Intel начала использовать технологию P2P в 1990 г., стремясь снизить расходы на разработку чипов. Компания создала собственную систему, названную NetBatch, которая объединяет более 10 тыс. компьютеров, предоставляя инженерам доступ к глобально распределенным вычислительным ресурсам.
Boeing применяет распределенные вычисления для выполнения ресурсоемких тестовых испытаний. Компания использует Napster-подобную модель сети, в которой серверы направляют трафик к назначенным узлам. «Нет такого одного компьютера, который отвечал бы нашим требованиям», - говорит Кен Невес (Ken Neves), директор исследовательского подразделения.
Потенциал технологий P2P привлек внимание и венчурного капитала. Так, Softbank Venture Capital инвестировал 13 млн долл. в компанию United Device, разрабатывающую технологии для трех рынков: вычисления для биотехнологической индустрии, качество обслуживания (QoS) и нагрузочные тесты для Web-сайтов, а также индексирование контента на базе метода «червячного» поиска, используемого рядом машин в Интернете.
В любом случае уже сегодня очевидны пять областей успешного применения сетей P2P. Это разделение файлов, разделение приложений, обеспечение целостности систем, распределенные вычисления и взаимодействие устройств. Нет сомнений, что в скором времени их станет еще больше.